repl.it linkrepl.it link (duplicated)Individual Project (iP):
Team Project (tP):
Week 12 [Fri, Oct 30th] - Topics
Detailed Table of Contents
- [W12.1] Boundary Value Analysis
- [W12.2] Combining Multiple Test Inputs
-
[W12.2a] Quality Assurance → Test Case Design → Combining Test Inputs → Why
-
[W12.2b] Quality Assurance → Test Case Design → Combining Test Inputs → Test input combination strategies
-
[W12.2c] Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: Each valid input at least once in a positive test case : OPTIONAL
-
[W12.2d] Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: No more than one invalid input in a test case : OPTIONAL
- [W12.3] Other QA Techniques
-
[W12.3a] Quality Assurance → Quality Assurance → Introduction → What
-
[W12.3b] Quality Assurance → Quality Assurance → Introduction → Validation versus verification
-
[W12.3c] Quality Assurance → Quality Assurance → Code Reviews → What
-
[W12.3d] Quality Assurance → Quality Assurance → Static Analysis → What
-
[W12.3e] Quality Assurance → Quality Assurance → Formal Verification → What
- [W12.4] SDLC Process Models: XP/Scrum
Guidance for the item(s) below:
Quality Assurance → Test Case Design → Boundary Value Analysis → What
Can explain boundary value analysis
Boundary Value Analysis (BVA) is a test case design heuristic that is based on the observation that bugs often result from incorrect handling of boundaries of equivalence partitions. This is not surprising, as the end points of boundaries are often used in branching instructions, etc., where the programmer can make mistakes.
The markCellAt(int x, int y) operation could contain code such as if (x > 0 && x <= (W-1)) which involves the boundaries of x’s equivalence partitions.
BVA suggests that when picking test inputs from an equivalence partition, values near boundaries (i.e. boundary values) are more likely to find bugs.
Boundary values are sometimes called corner cases.
Exercises
What BVA recommends
Boundary value analysis recommends testing only values that reside on the equivalence class boundary.
False
Explanation: It does not recommend testing only those values on the boundary. It merely suggests that values on and around a boundary are more likely to cause errors.
Quality Assurance → Test Case Design → Boundary Value Analysis → How
Can apply boundary value analysis
Typically, you should choose three values around the boundary to test: one value from the boundary, one value just below the boundary, and one value just above the boundary. The number of values to pick depends on other factors, such as the cost of each test case.
Some examples:
| Equivalence partition | Some possible test values (boundaries are in bold) |
|---|---|
|
[1-12] |
0,1,2, 11,12,13 |
|
[MIN_INT, 0] |
MIN_INT, MIN_INT+1, -1, 0 , 1 |
|
[any non-null String] |
Empty String, a String of maximum possible length |
|
[prime numbers] |
No specific boundary |
|
[non-empty Stack] |
Stack with: no elements, one element, two elements, no empty spaces, only one empty space |
Guidance for the item(s) below:
Earlier, you learned Equivalence Partitioning, Boundary Value Analysistwo heuristics that can improve the test case quality. Even when applying them, the number of test cases can increase when the SUT takes multiple inputs. Let's see how we can deal with such situations.
Quality Assurance → Test Case Design → Combining Test Inputs → Why
Can explain the need for strategies to combine test inputs
An SUT can take multiple inputs. You can select values for each input (using equivalence partitioning, boundary value analysis, or some other technique).
An SUT that takes multiple inputs and some values chosen for each input:
- Method to test:
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test:
Input Valid values to test Invalid values to test participation 0, 1, 19, 20 21, 22 projectGrade A, B, C, D, F isAbsent true, false examScore 0, 1, 69, 70, 71, 72
Testing all possible combinations is effective but not efficient. If you test all possible combinations for the above example, you need to test 6x5x2x6=360 cases. Doing so has a higher chance of discovering bugs (i.e. effective) but the number of test cases will be too high (i.e. not efficient). Therefore, you need smarter ways to combine test inputs that are both effective and efficient.
Quality Assurance → Test Case Design → Combining Test Inputs → Test input combination strategies
Can explain some basic test input combination strategies
Given below are some basic strategies for generating a set of test cases by combining multiple test inputs.
Let's assume the SUT has the following three inputs and you have selected the given values for testing:
SUT: foo(char p1, int p2, boolean p3)
Values to test:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
| p3 | T, F |
The all combinations strategy generates test cases for each unique combination of test inputs.
This strategy generates 3x3x2=18 test cases.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 1 | F |
| 3 | a | 2 | T |
| ... | ... | ... | ... |
| 18 | c | 3 | F |
The at least once strategy includes each test input at least once.
This strategy generates 3 test cases.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | b | 2 | F |
| 3 | c | 3 | VV/IV |
VV/IV = Any Valid Value / Any Invalid Value
The all pairs strategy creates test cases so that for any given pair of inputs, all combinations between them are tested. It is based on the observation that a bug is rarely the result of more than two interacting factors. The resulting number of test cases is lower than the all combinations strategy, but higher than the at least once approach.
This strategy generates 9 test cases:
See steps
Let's first consider inputs p1 and p2:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
These values can generate (a,1)(a,2)(a,3)(b,1)(b,2),...3x3=9 combinations, and the test cases should cover all of them.
Next, let's consider p1 and p3.
| Input | Values |
|---|---|
| p1 | a, b, c |
| p3 | T, F |
These values can generate (a,T)(a,F)(b,T)(b,F),...3x2=6 combinations, and the test cases should cover all of them.
Similarly, inputs p2 and p3 generate another 6 combinations.
The 9 test cases given below cover all the above 9+6+6 combinations.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | T |
| 3 | a | 3 | F |
| 4 | b | 1 | F |
| 5 | b | 2 | T |
| 6 | b | 3 | F |
| 7 | c | 1 | T |
| 8 | c | 2 | F |
| 9 | c | 3 | T |
A variation of this strategy is to test all pairs of inputs but only for inputs that could influence each other.
Testing all pairs between p1 and p3 only while ensuring all p2 values are tested at least once:
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | F |
| 3 | b | 3 | T |
| 4 | b | VV/IV | F |
| 5 | c | VV/IV | T |
| 6 | c | VV/IV | F |
The random strategy generates test cases using one of the other strategies and then picks a subset randomly (presumably because the original set of test cases is too big).
There are other strategies that can be used too.
Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: Each valid input at least once in a positive test case
Can apply heuristic ‘each valid input at least once in a positive test case’
Consider the following scenario.
SUT: printLabel(String fruitName, int unitPrice)
Selected values for fruitName (invalid values are underlined):
| Values | Explanation |
|---|---|
| Apple | Label format is round |
| Banana | Label format is oval |
| Cherry | Label format is square |
| Dog | Not a valid fruit |
Selected values for unitPrice:
| Values | Explanation |
|---|---|
| 1 | Only one digit |
| 20 | Two digits |
| 0 | Invalid because 0 is not a valid price |
| -1 | Invalid because negative prices are not allowed |
Suppose these are the test cases being considered.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print label |
| 2 | Banana | 20 | Print label |
| 3 | Cherry | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
It looks like the test cases were created using the at least once strategy. After running these tests, can you confirm that the square-format label printing is done correctly?
- Answer: No.
- Reason:
Cherry-- the only input that can produce a square-format label -- is in a negative test case which produces an error message instead of a label. If there is a bug in the code that prints labels in square-format, these tests cases will not trigger that bug.
In this case, a useful heuristic to apply is each valid input must appear at least once in a positive test case. Cherry is a valid test input and you must ensure that it appears at least once in a positive test case. Here are the updated test cases after applying that heuristic.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV = Any Valid Value
Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: No more than one invalid input in a test case
Quality Assurance → Test Case Design → Combining Test Inputs → Heuristic: Each Valid Input at Least Once in a Positive Test Case
Can apply heuristic ‘no more than one invalid input in a test case’
Consider the test cases designed in [Heuristic: each valid input at least once in a positive test case].
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV = Any Valid Value
After running these test cases, can you be sure that the error message “invalid price” is shown for negative prices?
- Answer: No.
- Reason:
-1-- the only input that is a negative price -– is in a test case that produces the error message “invalid fruit”.
In this case, a useful heuristic to apply is no more than one invalid input in a test case. After applying that, you get the following test cases.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | VV | -1 | Error message “invalid price" |
| 4.1 | Dog | VV | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV = Any Valid Value
Exercises
Can define test cases precisely
Applying the heuristics covered so far, we can determine the precise number of test cases required to test any given SUT effectively.
False
Explanation: These heuristics are, well, heuristics only. They will help you to make better decisions about test case design. However, they are speculative in nature (especially, when testing in black-box fashion) and cannot give you the precise number of test cases.
Guidance for the item(s) below:
Testing is the first thing that comes to mind when you hear 'Quality Assurance' but there are other QA techniques that can complement testing. Let's first take a step back and take a look at QA in general, followed by a look at some other QA techniques.
Quality Assurance → Quality Assurance → Introduction → What
Can explain software quality assurance
Software Quality Assurance (QA) is the process of ensuring that the software being built has the required levels of quality.
While testing is the most common activity used in QA, there are other complementary techniques such as static analysis, code reviews, and formal verification.
Quality Assurance → Quality Assurance → Introduction → Validation versus verification
Can explain validation and verification
Quality Assurance = Validation + Verification
QA involves checking two aspects:
- Validation: are you building the right system i.e., are the requirements correct?
- Verification: are you building the system right i.e., are the requirements implemented correctly?
Whether something belongs under validation or verification is not that important. What is more important is that both are done, instead of limiting to only verification (i.e., remember that the requirements can be wrong too).
Exercises
Statements about validation and verification
Choose the correct statements about validation and verification.
- a. Validation: Are we building the right product?, Verification: Are we building the product right?
- b. It is very important to clearly distinguish between validation and verification.
- c. The important thing about validation and verification is to remember to pay adequate attention to both.
- d. Developer-testing is more about verification than validation.
- e. QA covers both validation and verification.
- f. A system crash is more likely to be a verification failure than a validation failure.
(a)(b)(c)(d)(e)(f)
Explanation:
Whether something belongs under validation or verification is not that important. What is more important is that we do both.
Developer testing is more about finding bugs in the code, rather than bugs in the requirements.
In QA, system testing is more about verification (does the system follow the specification?) and acceptance testing is more about validation (does the system solve the user’s problem?).
A system crash is more likely to be a bug in the code, not in the requirements.
Quality Assurance → Quality Assurance → Code Reviews → What
Can explain code reviews
Code review is the systematic examination of code with the intention of finding where the code can be improved.
Reviews can be done in various forms. Some examples below:
-
Pull Request reviews
- Project Management Platforms such as GitHub and BitBucket allow the new code to be proposed as Pull Requests and provide the ability for others to review the code in the PR.
-
In pair programming
- As pair programming involves two programmers working on the same code at the same time, there is an implicit review of the code by the other member of the pair.
Pair programming:
Pair programming is an agile software development technique in which two programmers work together at one workstation. One, the driver, writes code while the other, the observer or navigator, reviews each line of code as it is typed in. The two programmers switch roles frequently. [source: Wikipedia]

A good introduction to pair programming:
-
Formal inspections
-
Inspections involve a group of people systematically examining project artifacts to discover defects. Members of the inspection team play various roles during the process, such as:
- the author - the creator of the artifact
- the moderator - the planner and executor of the inspection meeting
- the secretary - the recorder of the findings of the inspection
- the inspector/reviewer - the one who inspects/reviews the artifact
-
Advantages of code review over testing:
- It can detect functionality defects as well as other problems such as coding standard violations.
- It can verify non-code artifacts and incomplete code.
- It does not require test drivers or stubs.
Disadvantages:
- It is a manual process and therefore, error prone.
Resources
- 10 tips for reviewing code you don’t like - a blog post by David Lloyd (a Red Hat developer).
Quality Assurance → Quality Assurance → Static Analysis → What
Can explain static analysis
Static analysis: Static analysis is the analysis of code without actually executing the code.
Static analysis of code can find useful information such as unused variables, unhandled exceptions, style errors, and statistics. Most modern IDEs come with some inbuilt static analysis capabilities. For example, an IDE can highlight unused variables as you type the code into the editor.
The term static in static analysis refers to the fact that the code is analyzed without executing the code. In contrast, dynamic analysis requires the code to be executed to gather additional information about the code e.g., performance characteristics.
Higher-end static analysis tools (static analyzers) can perform more complex analysis such as locating potential bugs, memory leaks, inefficient code structures, etc.
Some example static analyzers for Java: CheckStyle, PMD, FindBugs
Linters are a subset of static analyzers that specifically aim to locate areas where the code can be made 'cleaner'.
Quality Assurance → Quality Assurance → Formal Verification → What
Can explain formal verification
Formal verification uses mathematical techniques to prove the correctness of a program.
An introduction to Formal Methods
by Eric Hehner
Advantages:
- Formal verification can be used to prove the absence of errors. In contrast, testing can only prove the presence of errors, not their absence.
Disadvantages:
- It only proves the compliance with the specification, but not the actual utility of the software.
- It requires highly specialized notations and knowledge which makes it an expensive technique to administer. Therefore, formal verifications are more commonly used in safety-critical software such as flight control systems.
Exercises
Absence of errors
Testing cannot prove the absence of errors. It can only prove the presence of errors. However, formal methods can prove the absence of errors.
True
Explanation: While using formal methods is more expensive than testing, it can indeed prove the correctness of a piece of software conclusively, in certain contexts. Getting such proof via testing requires exhaustive testing, which is not practical to do in most cases.
Guidance for the item(s) below:
In a previous week, you learned about sequential and iterative ways of doing a software. Now, let us take a quick look at a couple of well-known processes used in the industry, both of which fall into a category called agile processes.
Project Management → SDLC Process Models → Introduction → Agile models
Can explain agile process models
In 2001, a group of prominent software engineering practitioners met and brainstormed for an alternative to documentation-driven, heavyweight software development processes that were used in most large projects at the time. This resulted in something called the agile manifesto (a vision statement of what they were looking to do).
You are uncovering better ways of developing software by doing it and helping others do it.
Through this work you have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, you value the items on the left more.
-- Extract from the Agile Manifesto
Subsequently, some of the signatories of the manifesto went on to create process models that try to follow it. These processes are collectively called agile processes. Some of the key features of agile approaches are:
- Requirements are prioritized based on the needs of the user, are clarified regularly (at times almost on a daily basis) with the entire project team, and are factored into the development schedule as appropriate.
- Instead of doing a very elaborate and detailed design and a project plan for the whole project, the team works based on a rough project plan and a high level design that evolves as the project goes on.
- There is a strong emphasis on complete transparency and responsibility sharing among the team members. The team is responsible together for the delivery of the product. Team members are accountable, and regularly and openly share progress with each other and with the user.
There are a number of agile processes in the development world today. eXtreme Programming (XP) and Scrum are two of the well-known ones.
Exercises
Statements about agile processes
Choose the correct statements about agile processes.
- a. They value working software over comprehensive documentation.
- b. They value responding to change over following a plan.
- c. They may not be suitable for some type of projects.
- d. XP and Scrum are agile processes.
(a)(b)(c)(d)
Project Management → SDLC Process Models → Scrum
Can explain scrum
This description of Scrum was adapted from Wikipedia [retrieved on 18/10/2011], emphasis added:
Scrum is a process skeleton that contains sets of practices and predefined roles. The main roles in Scrum are:
- The Scrum Master, who maintains the processes (typically in lieu of a project manager)
- The Product Owner, who represents the stakeholders and the business
- The Team, a cross-functional group who do the actual analysis, design, implementation, testing, etc.
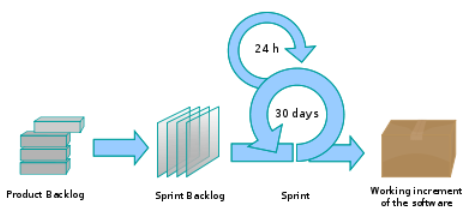
A Scrum project is divided into iterations called Sprints. A sprint is the basic unit of development in Scrum. Sprints tend to last between one week and one month, and are a timeboxed (i.e. restricted to a specific duration) effort of a constant length.
Each sprint is preceded by a planning meeting, where the tasks for the sprint are identified and an estimated commitment for the sprint goal is made, and followed by a review or retrospective meeting, where the progress is reviewed and lessons for the next sprint are identified.
During each sprint, the team creates a potentially deliverable product increment (for example, working and tested software). The set of features that go into a sprint come from the product backlog, which is a prioritized set of high level requirements of work to be done. Which backlog items go into the sprint is determined during the sprint planning meeting. During this meeting, the Product Owner informs the team of the items in the product backlog that he or she wants completed. The team then determines how much of this they can commit to complete during the next sprint, and records this in the sprint backlog. During a sprint, no one is allowed to change the sprint backlog, which means that the requirements are frozen for that sprint. Development is timeboxed such that the sprint must end on time; if requirements are not completed for any reason they are left out and returned to the product backlog. After a sprint is completed, the team demonstrates the use of the software.
Scrum enables the creation of self-organizing teams by encouraging co-location of all team members, and verbal communication between all team members and disciplines in the project.
A key principle of Scrum is its recognition that during a project the customers can change their minds about what they want and need (often called requirements churn), and that unpredicted challenges cannot be easily addressed in a traditional predictive or planned manner. As such, Scrum adopts an empirical approach—accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team’s ability to deliver quickly and respond to emerging requirements.
Daily Scrum is another key scrum practice. The description below was adapted from https://www.mountaingoatsoftware.com (emphasis added):
In Scrum, on each day of a sprint, the team holds a daily scrum meeting called the "daily scrum.” Meetings are typically held in the same location and at the same time each day. Ideally, a daily scrum meeting is held in the morning, as it helps set the context for the coming day's work. These scrum meetings are strictly time-boxed to 15 minutes. This keeps the discussion brisk but relevant.
...
During the daily scrum, each team member answers the following three questions:
- What did you do yesterday?
- What will you do today?
- Are there any impediments in your way?
...
The daily scrum meeting is not used as a problem-solving or issue resolution meeting. Issues that are raised are taken offline and usually dealt with by the relevant subgroup immediately after the meeting.
Intro to Scrum in Under 10 Minutes
(This is not an endorsement of the product mentioned in the video)
Project Management → SDLC Process Models → XP
Can explain XP
The following description was adapted from the XP home page, emphasis added:
Extreme Programming (XP) stresses customer satisfaction. Instead of delivering everything you could possibly want on some date far in the future, this process delivers the software you need as you need it.
XP aims to empower developers to confidently respond to changing customer requirements, even late in the life cycle.
XP emphasizes teamwork. Managers, customers, and developers are all equal partners in a collaborative team. XP implements a simple, yet effective environment enabling teams to become highly productive. The team self-organizes around the problem to solve it as efficiently as possible.
XP aims to improve a software project in five essential ways: communication, simplicity, feedback, respect, and courage. Extreme Programmers constantly communicate with their customers and fellow programmers. They keep their design simple and clean. They get feedback by testing their software starting on day one. Every small success deepens their respect for the unique contributions of each and every team member. With this foundation, Extreme Programmers are able to courageously respond to changing requirements and technology.
XP has a set of simple rules. XP is a lot like a jig saw puzzle with many small pieces. Individually the pieces make no sense, but when combined together a complete picture can be seen. This flow chart shows how Extreme Programming's rules work together.
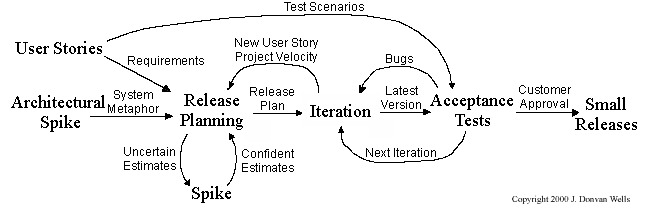
Pair programming, CRC cards, project velocity, and standup meetings are some interesting topics related to XP. Refer to extremeprogramming.org to find out more about XP.